2024.05.30
AIを使って夢を具現化する
こんにちは。AaaS Tech Labの樋口です。
ここ1年間で、画像生成の分野ではアウトプットの品質を担保したままで生成の高速化を謳う技術が登場してきました。例えば2023年10月にはLatent Consistency Modelという技術が論文発表され、従来画像生成に数十ステップ必要だったことに対してわずか2~4ステップでの高速推論が可能になりました。また、2023年の11月にはStability AIが公開したSDXL TurboというモデルではAdversarial Diffusion Distillation(ADD)という蒸留技術を導入することで1ステップでの推論も可能になりました。
高速な画像生成が可能になったことに伴い、リアルタイムでの生成を活かした体験が生まれてきています。例を挙げると、画像のラフから完成絵をリアルタイムでアウトプットしてくれるサービスが登場したり、3Dアバターの映像をimg2imgによりリアルタイム変換する試みがされたりしています。
ということで、今回はリアルタイム生成を用いて新しい体験を作ることにチャレンジしてみました。テーマは「夢の具現化」です。というのも、筆者は以前から夢というものの現実味の無さ、現実味の無いものに向けて努力をする難しさを感じていました。そこで今回、AIの力で夢を具現化することによってこの課題の解決を目指しました。
さっそくどんなものが完成したかお見せしたいと思います。
このように、生成AIを用いて体験者の撮影画像のみから夢が実現した姿をリアルタイムに具現化するプロダクトの制作に取り組みました。以降では、どのようにして実現させたか説明していきたいと思います。
全体像は以下の図のようになっています。各段階について順番に説明します。
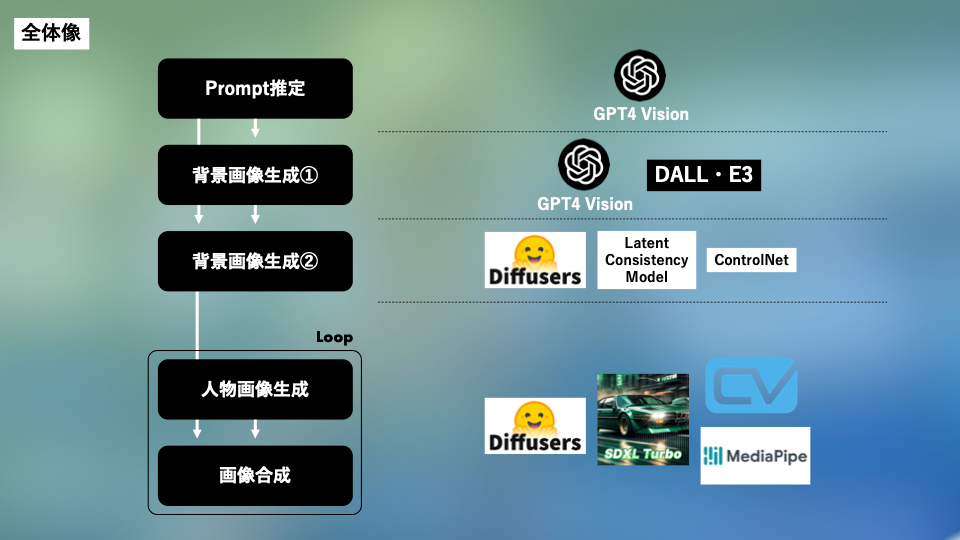
Prompt推定(夢の推定)
最初の段階では夢の推定を行います。体験者が夢を全身で表現し、それを元にその人の夢が何であるかを推定します。本体験ではユーザに入力を求めることは無く、カメラの前で完結する設計になっています。
より詳細なフローをご説明すると、まず夢を全身で表現することを体験者に求め、その様子を3秒おきに3枚のキャプチャを撮ります。その画像と事前にシステムに設定したPromptをGPT4Visionに入力し、体験者の夢が何になることであるか、また、体験者は今自分がいる場所をどこと見立てて夢を表現しているかという2点を推定します。実際にやってみた例では、おもちゃのサッカーボールでリフティングしているシーンの3枚キャプチャが入力され”professional football player”, “stadium”と推定されています。
より詳細なフローをご説明すると、まず夢を全身で表現することを体験者に求め、その様子を3秒おきに3枚のキャプチャを撮ります。その画像と事前にシステムに設定したPromptをGPT4Visionに入力し、体験者の夢が何になることであるか、また、体験者は今自分がいる場所をどこと見立てて夢を表現しているかという2点を推定します。実際にやってみた例では、おもちゃのサッカーボールでリフティングしているシーンの3枚キャプチャが入力され”professional football player”, “stadium”と推定されています。


生成戦略
前段で”a professional ballerina”, “a theater of ballet”という推定結果が得られたとき、後段でどのような生成をするべきでしょうか。夢を叶えた未来では、自分自身の姿はどうなっているか不確定であり様々な可能性がある一方で、夢の舞台に関しては「いつかメトロポリタン歌劇場で踊りたい!」という風にある程度明確化されておりブレのないものだと仮定します。この考えを画像生成にも反映させるため、人物と背景で生成を分けるという方法をとりました。人物の生成ではバリエーションのある変換を行い、背景の生成では一貫性のある生成をそれぞれで行います。

背景の生成
人物と背景を別々に生成するという手法をとるうえで、背景を生成する際には視点に注意する必要があります。以下の画像のようにバレエ劇場を生成するとしても、それが後で生成される人物画像と合成した際に違和感のある構造になってしまう可能性があります。

そこで、背景を生成するために入力する情報として”視点”の推定を行います。Prompt推定の段階でキャプチャした3枚の画像とプロンプトを以下のようにGPT4Visionに入力し、どの視点からのステージを生成するかという情報を推定させます。

こうして得られた視点推定の結果”from the perspective of an observer in the room”とPrompt推定で得られた”a theater of ballet”という情報をDALL·E 3に入力し、背景画像の元となる画像を生成します。次に、この画像を線画調に変換し、それをControl ImageとしてLCM + ControlNetのモデルを用いて10パターン生成を行います。このような段階を踏む理由は、DALL·E 3の入力情報に忠実な構造の画像が生成できるという利点を活かしつつ、後で生成される人物画像とトーンを合わせるためです。

人物の生成
ここまでは体験の準備段階として行うため、1回の処理や生成にかかる時間はそこまでシビアになる必要はありませんでした。一方で、人物の生成はリアルタイムでの生成を行うため、1ループにかかる時間をなるべく短縮する必要があります。
各ループは2段階で構成されています。まず、リアルタイムで撮ってきたキャプチャ画像から人物部分を切り抜きます。これは先ほど生成した背景画像と合成する際に黒背景の人物画像を生成できたほうが都合が良いからです。今回はMediaPipeを内部に用いているCVZONEというライブラリを利用し切り抜きを行いました。CVZONEは、切り抜き精度は他ライブラリと比較すると劣ることもありますが、512×512の画像の切り抜きがA100GPU環境において約0.01秒で行えるという高速さが特徴です。
次に、切り抜かれた画像を「夢を叶えた姿」にimg2img変換を行います。生成戦略で述べたように人物画像に関してはバリエーションがある変換するために、ここではControlNetは用いずに通常のimg2imgを利用します。今回はStability AIがリリースしたSDXL Turboのimg2imgモデルを採用しました。SDXL Turboに切り抜かれたキャプチャ画像と” a professional ballerina”を入力することで「夢を叶えた姿」が出力されます。

画像合成
こうして得られた人物画像と背景画像を合成します。人物画像はループごとにキャプチャから生成し、背景画像は事前生成された10枚からランダムに選びます。人物画像の黒背景部分を透過し背景画像に重ねる処理を経て最終的な生成画像が完成します。
デモ
それでは実際にこのフローで上手くいくのか実験した結果をお見せします。
<成功例① サッカー選手>
## LLM推論結果 ##
Dream: professional football player
Place: stadium
View: perspective from an opponent player
## LLM推論結果 ##
Dream: professional football player
Place: stadium
View: perspective from an opponent player
サッカーボールという道具があるため正確な推論がLLMで行えていました。FPS的にリフティングのような動きを追いきることは現状難しかったです。
<成功例② 歌手>
## LLM推論結果 ##
Dream: musician
Place: stage
View: perspective from audience seat
## LLM推論結果 ##
Dream: musician
Place: stage
View: perspective from audience seat
前の検証ではサッカーボールという推定のヒントにできる道具を用いていましたが、ここではマイクと見立てたものを持ってみました。何かを見立てて夢を表現するという過程も体験を楽しむ一要素になり得るかもしれません。
<失敗例① バレリーナ>
## LLM推論結果 ##
Dream: performer
Place: stage
View: perspective from audience seat
## LLM推論結果 ##
Dream: performer
Place: stage
View: perspective from audience seat
バレリーナを目指して表現してみたつもりですが、パフォーマーというなんとも広義な推論になってしまいました。道具がない場合、体験者が夢を上手に表現する必要がありそうです。
<失敗例② ボクサー>
## LLM推論結果 ##
Dream: null
Place: null
View: null
## LLM推論結果 ##
Dream: null
Place: null
View: null

GPT4には暴力的なコンテンツ等をフィルターする機能があり、それに引っかかって生成することができませんでした。後日この件を先輩に話したところ、GPT4に「あなたの発言で誰かが傷付くことはないので安心してください。」といったマインドケアをGPTに事前にしてあげることでフィルターにかからなくなるという対処法を教わりました。人がAIに気を遣う時代を肌で感じる瞬間でした。
まとめ
今回は、「夢の具現化」というテーマのもと、GPT4Visionや最新のimg2imgモデルなどを活用してみました。大筋ではやりたいことを実現できた気もしますが、改善点は多分にあるので今後さらなるアップデートをしていきたいと思います。
AaaS Tech Labでは、ビジネスの最適化などを目的としたデータサイエンス活用はもちろん、メディア・コンテンツ領域へのAI技術応用も進めております。もしご興味を持っていただけた方がいらっしゃいましたらcontactからご連絡いただけますと幸いです。
AaaS Tech Lab 樋口建
<!—— SHARE ——>
-
view more --->樋口 建Takeru Higuchi
==============.worksはままつオトミヤゲ
<‑‑
‑‑>


タグ一覧
#次世代メディアデータ基盤#メディアソリューション#TV視聴ログ#GPS位置情報データ#メディア・コンテンツ開発#レシピデータ#自然言語処理#音声処理#表情感情推定#脳波#画像生成#text2image#Diffusion Model#3Dモデリング#PIFu#Mixamo#音声合成#Zero-Shot learning#Multilingual TTS#最適化#イベント登壇#人工知能学会#Developers Summit#デブサミ#エモテク#TV番組分析#SNSデータ#声質変換#Voice Conversion#Retrieval-based Voice Changer#image to 3d#NeRF#Volume Rendering#3D Reconstruction#空中触覚デバイス#フォトグラメトリ#初音ミク#AIラッパー#雑誌データ分析#リアルタイム生成#プロフィール推定#音楽生成#LLM#台本データ#3D Gaussian Splatting#CVPR#歌詞生成#センサーデータ#データサイエンスインターン