2022.07.28
Text to Imageによるmemberページのエフェクト作成
こんにちは。AaaS Tech Labの小山田です。
AaaS Tech LabのWebサイトを先日リリースさせていただきました。
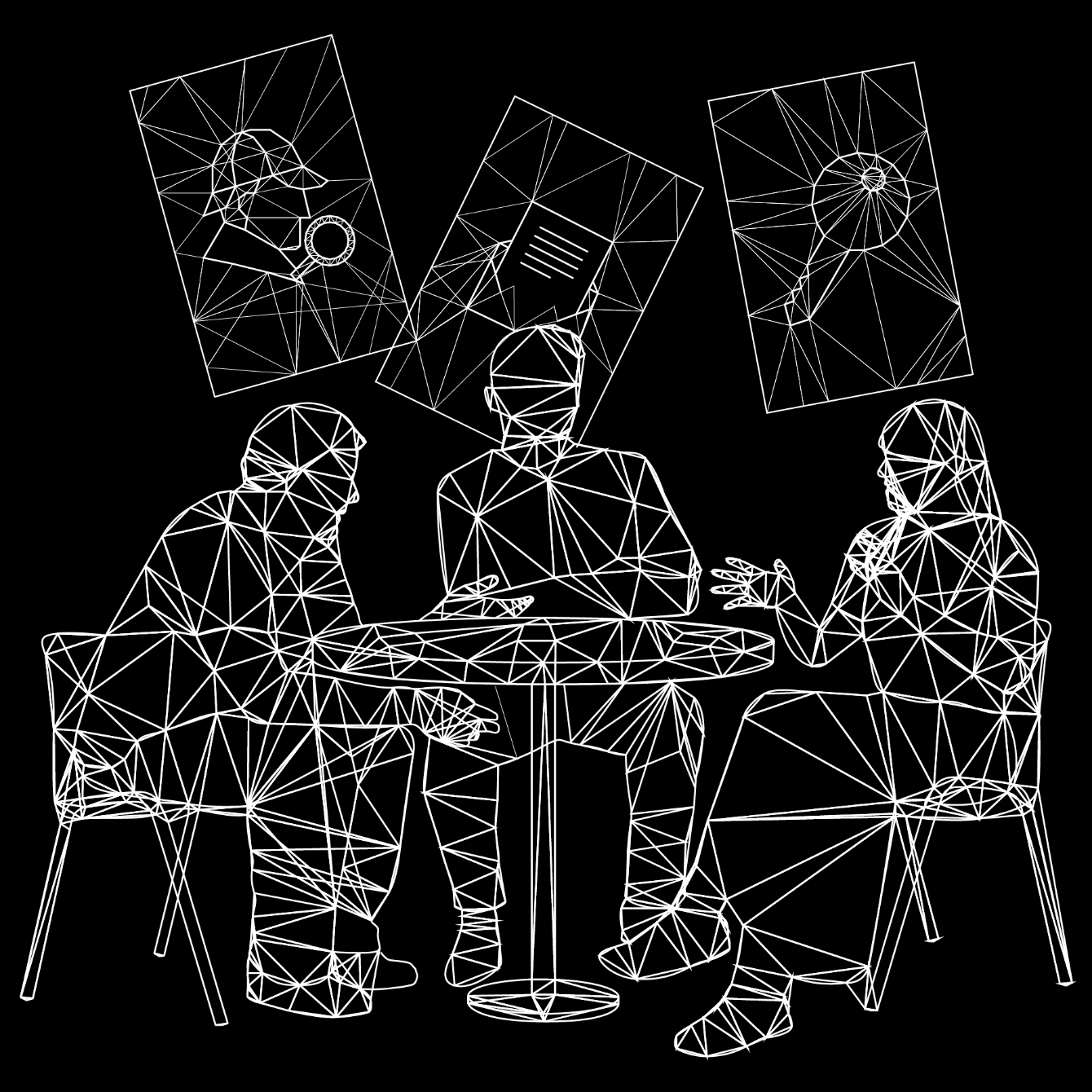
Webサイト内のmemberページ(各メンバーのページ内)では、メンバーの顔がくり抜かれて映像が流れる仕組みになっています。顔の内部に流れる映像は、メンバーから募集した趣味/嗜好/大切にする言葉などを、Text to Imageにより生成したグラフィックから作られています。
この映像制作は私が担当したのですが、本記事では具体的にどんなことをやったのか少しお話ししたいと思います。
ぜひ、各メンバーのページと一緒にご一読いただけると嬉しく思います。
Webサイト内のmemberページ(各メンバーのページ内)では、メンバーの顔がくり抜かれて映像が流れる仕組みになっています。顔の内部に流れる映像は、メンバーから募集した趣味/嗜好/大切にする言葉などを、Text to Imageにより生成したグラフィックから作られています。
この映像制作は私が担当したのですが、本記事では具体的にどんなことをやったのか少しお話ししたいと思います。
ぜひ、各メンバーのページと一緒にご一読いただけると嬉しく思います。

コンセプト
まずは、memberページのエフェクトに関するコンセプトをまとめます。
1つ目は、各メンバーの趣味嗜好や大切にしていることを文章ではなく、グラフィックという直感的な形で表現するということです。自己紹介の場で、「趣味は旅行や音楽鑑賞です。」といった話を聞くことが多いかと思います。こういったお決まりのような挨拶を、テクノロジー的にアップデートし、生活者の皆さんに届けられないかと考えました。
2つ目は、頭の中を覗き込むような体験を作りたかったということです。人の頭の中を覗き込むことができると、今よりもrawデータに近い情報が取得できて、他者への理解が進むのではないかと妄想しました。もちろん現状では現実的ではないので、テキストという形でメンバーの頭の中の情報をもらい、AIで映像化、頭や顔に相当する部分をくりぬいて映像を流すというステップを踏みました。
こういった形で、なんとなくカッコつけてコンセプトを語ってしまいましたが、個人的に学生の頃から生成系モデルの研究をしていたこともあり、どこか活用する場を作りたかったというのが正直なところです…笑。
1つ目は、各メンバーの趣味嗜好や大切にしていることを文章ではなく、グラフィックという直感的な形で表現するということです。自己紹介の場で、「趣味は旅行や音楽鑑賞です。」といった話を聞くことが多いかと思います。こういったお決まりのような挨拶を、テクノロジー的にアップデートし、生活者の皆さんに届けられないかと考えました。
2つ目は、頭の中を覗き込むような体験を作りたかったということです。人の頭の中を覗き込むことができると、今よりもrawデータに近い情報が取得できて、他者への理解が進むのではないかと妄想しました。もちろん現状では現実的ではないので、テキストという形でメンバーの頭の中の情報をもらい、AIで映像化、頭や顔に相当する部分をくりぬいて映像を流すというステップを踏みました。
こういった形で、なんとなくカッコつけてコンセプトを語ってしまいましたが、個人的に学生の頃から生成系モデルの研究をしていたこともあり、どこか活用する場を作りたかったというのが正直なところです…笑。
技術概要
次に、少し技術的な概要に触れます。
Text to Imageとは、その名の通り、Text(文章や単語)をInputとし、Image(画像)を生成する技術を指します。
最近では、DALL-E[1]や DALL-E 2[2]、Imagen[3]などの技術が発表され、生成される画像の品質や多様性の高さから大きな注目を浴びているかと思います。
こういったText to Image系の技術が飛躍的に発展している裏には、CLIP[4]という画像とテキストの対応関係を学習できる技術や、Diffusion Model[5]という生成モデルが提案されてきたという流れがあります。
ここでは理論的な解説は省きますが、SonyによるYouTubeチャンネル[6]にて、上述の技術などに関する解説動画がアップされていますので、ご興味のある方はご覧になっていただくと理解が進むかもしれません。
Text to Imageとは、その名の通り、Text(文章や単語)をInputとし、Image(画像)を生成する技術を指します。
最近では、DALL-E[1]や DALL-E 2[2]、Imagen[3]などの技術が発表され、生成される画像の品質や多様性の高さから大きな注目を浴びているかと思います。
こういったText to Image系の技術が飛躍的に発展している裏には、CLIP[4]という画像とテキストの対応関係を学習できる技術や、Diffusion Model[5]という生成モデルが提案されてきたという流れがあります。
ここでは理論的な解説は省きますが、SonyによるYouTubeチャンネル[6]にて、上述の技術などに関する解説動画がアップされていますので、ご興味のある方はご覧になっていただくと理解が進むかもしれません。
制作プロセス
では、今回生成した映像ではどういったテキストをInputするなどしたのかをお話しします。
例として、Labメンバー 青山[7]の映像について考えます
青山からは、「A music on the programmatic world echoes through the air.」という文章をもらいました。
まず私は、この文章を「音楽」「テクノロジー/SF的な都市」「空気の流れ」という形で要素分解しました。
そして、青山の元文章をそのままInputするのではなく、下記のような4つの文章としてモデルに与えました。
Music made by the breath of God.
Electrons are drifting through the world.
The music score generated by brain machine.
James Gurney, Science-Fiction, matte painting, Cyberpunk, Pablo Ruiz Picasso.
実験する中での気づきを少し書いておきます。
「空気の流れ」といったものは、Airなどで表現するよりもWindやBreathなど空気の動きを感じられる単語にした方がグラフィックに流動性が生まれる気がしました。
また、4つ目の文章では、「James Gurney, Science-Fiction, …」といった文言が含まれますが、CLIPなどを使う場合、具体的なアーティスト名やSF的な単語をInputするとガラッと生成結果の画風が変化する場合があります。今回はSF感の表現のために4つ目のようなテキストをInputしました。
こういった工夫により、ある程度はそれらしいグラフィックが生成できますが、なかなかInputするTextだけを変化させても、意図したグラフィックとはならないケースもあります。今回は少し細部にまで踏み込んで映像を生成したかったので、下記のような画像をTextと一緒に活用しました。
例として、Labメンバー 青山[7]の映像について考えます
青山からは、「A music on the programmatic world echoes through the air.」という文章をもらいました。
まず私は、この文章を「音楽」「テクノロジー/SF的な都市」「空気の流れ」という形で要素分解しました。
そして、青山の元文章をそのままInputするのではなく、下記のような4つの文章としてモデルに与えました。
Music made by the breath of God.
Electrons are drifting through the world.
The music score generated by brain machine.
James Gurney, Science-Fiction, matte painting, Cyberpunk, Pablo Ruiz Picasso.
実験する中での気づきを少し書いておきます。
「空気の流れ」といったものは、Airなどで表現するよりもWindやBreathなど空気の動きを感じられる単語にした方がグラフィックに流動性が生まれる気がしました。
また、4つ目の文章では、「James Gurney, Science-Fiction, …」といった文言が含まれますが、CLIPなどを使う場合、具体的なアーティスト名やSF的な単語をInputするとガラッと生成結果の画風が変化する場合があります。今回はSF感の表現のために4つ目のようなテキストをInputしました。
こういった工夫により、ある程度はそれらしいグラフィックが生成できますが、なかなかInputするTextだけを変化させても、意図したグラフィックとはならないケースもあります。今回は少し細部にまで踏み込んで映像を生成したかったので、下記のような画像をTextと一緒に活用しました。

Diffusion Modelは、ノイズ画像のようなものから多段階的にノイズを除去するイメージで画像を生成します。このとき初期段階のノイズ画像として、何らかの画像にノイズを加えたもの与え、そこからノイズ除去を行うと元画像に似た画像の生成が可能です。また、比較的強いノイズを画像に加えた状態からノイズ除去を行っていくと、色味などの大まかな特徴は保ちつつ、細部などはまったく異なる画像を生成することも可能です。
今回は、上記のような都市の上に楽譜を載せた画像を使用し、色味や五線譜などは保ちつつ、元画像とは異なる雰囲気のグラフィックが生成されるように調整しました。楽譜を載せたのは「音楽」を表現する為であり、背景が都市になっているのは色味や複雑性がサイバー感の表現にちょうど良さそうだと思ったからです。
こういった工夫の結果、実際に生成された静止画は下記です。
今回は、上記のような都市の上に楽譜を載せた画像を使用し、色味や五線譜などは保ちつつ、元画像とは異なる雰囲気のグラフィックが生成されるように調整しました。楽譜を載せたのは「音楽」を表現する為であり、背景が都市になっているのは色味や複雑性がサイバー感の表現にちょうど良さそうだと思ったからです。
こういった工夫の結果、実際に生成された静止画は下記です。

Inputに使用した楽譜の五線譜が自然と溶け込み、色味も青みがかったネオンっぽさが残っています。また、「Breath」を表現したと思われる流動的な線や、「the music score generated by brain machine.」に対応するような脳が五線譜と混じり合った表現も確認できるかと思います。
こうして、青山の趣味/嗜好を表現した静止画までは生成できました。
最後に映像として動かす部分ですが、こちらも画像をInputとして活用する部分と似た処理で実現可能です。
Diffusion Modelにおいて、ある程度までノイズ除去した画像を、少し右にズラします。そして、少し右にずらした状態からノイズ除去を再開します。すると、最終的に生成される画像も、元々生成されるはずだった画像と比較して、少し右にズレます。これを繰り返し、徐々に右にズラしながら画像を生成、映像としてつなぎ合わせると、徐々に右へとスクロールする映像が得られます。こうして、青山の映像は制作されました。
ちなみにですが、こういったズラしたりする処理は、深度推定系のアプローチと組み合わせることで、3次元方向に回転させたりも可能です。なので、例えば、ある物体を中心にその周りを3次元的に一周するような映像も制作できるかもしれません。
こうして、青山の趣味/嗜好を表現した静止画までは生成できました。
最後に映像として動かす部分ですが、こちらも画像をInputとして活用する部分と似た処理で実現可能です。
Diffusion Modelにおいて、ある程度までノイズ除去した画像を、少し右にズラします。そして、少し右にずらした状態からノイズ除去を再開します。すると、最終的に生成される画像も、元々生成されるはずだった画像と比較して、少し右にズレます。これを繰り返し、徐々に右にズラしながら画像を生成、映像としてつなぎ合わせると、徐々に右へとスクロールする映像が得られます。こうして、青山の映像は制作されました。
ちなみにですが、こういったズラしたりする処理は、深度推定系のアプローチと組み合わせることで、3次元方向に回転させたりも可能です。なので、例えば、ある物体を中心にその周りを3次元的に一周するような映像も制作できるかもしれません。
最後に
今回は、Text to Imageを活用して、AaaS Tech Labのmemberページ エフェクトを作成したお話でした。使用したモデルがDALL-E 2などのようなものではないので、人や物体などを崩れることなく鮮明に生成するというのは断念したのですが、AIらしい(少なくとも私では描けないような)一風変わったグラフィックが生成できたのではないかと思います。
(私としては、だいぶ前にDALL-E 2のWait listに登録したので、早く使ってみたいなと待ち遠しい今日この頃です…。)
こういった形で、AaaS Tech Labでは、ビジネスの最適化などを目的としたデータサイエンス活用はもちろん、メディア・コンテンツ領域へのAI技術応用も進めております。
もしご興味を持っていただけた方がいらっしゃいましたら、worksをご覧いただいたり、contactからご連絡いただけたりしますと幸いです。
AaaS Tech Lab 小山田圭佑
(私としては、だいぶ前にDALL-E 2のWait listに登録したので、早く使ってみたいなと待ち遠しい今日この頃です…。)
こういった形で、AaaS Tech Labでは、ビジネスの最適化などを目的としたデータサイエンス活用はもちろん、メディア・コンテンツ領域へのAI技術応用も進めております。
もしご興味を持っていただけた方がいらっしゃいましたら、worksをご覧いただいたり、contactからご連絡いただけたりしますと幸いです。
AaaS Tech Lab 小山田圭佑
<!—— SHARE ——>
-
view more --->小山田 圭佑Keisuke Oyamada
==============
<‑‑
‑‑>


タグ一覧
#次世代メディアデータ基盤#メディアソリューション#TV視聴ログ#GPS位置情報データ#メディア・コンテンツ開発#レシピデータ#自然言語処理#音声処理#表情感情推定#脳波#画像生成#text2image#Diffusion Model#3Dモデリング#PIFu#Mixamo#音声合成#Zero-Shot learning#Multilingual TTS#最適化#イベント登壇#人工知能学会#Developers Summit#デブサミ#エモテク#TV番組分析#SNSデータ#声質変換#Voice Conversion#Retrieval-based Voice Changer#image to 3d#NeRF#Volume Rendering#3D Reconstruction#空中触覚デバイス#フォトグラメトリ#初音ミク#AIラッパー#雑誌データ分析#リアルタイム生成#プロフィール推定#音楽生成#LLM#台本データ#3D Gaussian Splatting#CVPR#歌詞生成#センサーデータ#データサイエンスインターン